VESPA: software to facilitate genomic annotation of prokaryotic organisms through integration of proteomic and transcriptomic data
Peterson E.S., McCue L.A., Schrimpe-Rutledge A.C., Jensen J.L., Walker H., Kobold M.A., Webb S.R., Payne S.H., Ansong C., Adkins J.N., Cannon W.R, Webb-Robertson B.J., VESPA: software to facilitate genomic annotation of prokaryotic organisms through integration of proteomic and transcriptomic data. BMC Genomics. 2012 Apr 5;13:131. doi: 10.1186/1471-2164-13-131
Abstract
The procedural aspects of genome sequencing and assembly have become relatively inexpensive, yet the full, accurate structural annotation of these genomes remains a challenge. Next-generation sequencing transcriptomics (RNA-Seq), global microarrays, and tandem mass spectrometry (MS/MS)-based proteomics have demonstrated immense value to genome curators as individual sources of information, however, integrating these data types to validate and improve structural annotation remains a major challenge. Current visual and statistical analytic tools are focused on a single data type, or existing software tools are retrofitted to analyze new data forms. We present Visual Exploration and Statistics to Promote Annotation (VESPA) is a new interactive visual analysis software tool focused on assisting scientists with the annotation of prokaryotic genomes though the integration of proteomics and transcriptomics data with current genome location coordinates.
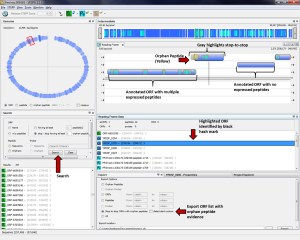
VESPA is a desktop Java™ application that integrates high-throughput proteomics data (peptide-centric) and transcriptomics (probe or RNA-Seq) data into a genomic context, all of which can be visualized at three levels of genomic resolution. Data is interrogated via searches linked to the genome visualizations to find regions with high likelihood of mis-annotation. Search results are linked to exports for further validation outside of VESPA or potential coding-regions can be analyzed concurrently with the software through interaction with BLAST. VESPA is demonstrated on two use cases (Yersinia pestis Pestoides F and Synechococcus sp. PCC 7002) to demonstrate the rapid manner in which mis-annotations can be found and explored in VESPA using either proteomics data alone, or in combination with transcriptomic data.
VESPA is an interactive visual analytics tool that integrates high-throughput data into a genomic context to facilitate the discovery of structural mis-annotations in prokaryotic genomes. Data is evaluated via visual analysis across multiple levels of genomic resolution, linked searches and interaction with existing bioinformatics tools. We highlight the novel functionality of VESPA and core programming requirements for visualization of these large heterogeneous datasets for a client-side application. The software is freely available at https://www.biopilot.org/docs/Software/Vespa.php




